Lai apmierinātu mākoņpakalpojumu vajadzības, tīkls pakāpeniski tiek sadalīts apakštīklā (Underlay) un pārklājuma (Overlay). Apakštīkls ir fiziskas iekārtas, piemēram, maršrutēšana un komutācija tradicionālajā datu centrā, kas joprojām tic stabilitātes koncepcijai un nodrošina uzticamas tīkla datu pārraides iespējas. Pārklājums ir tajā iekapsulēts biznesa tīkls, kas ir tuvāk pakalpojumam, izmantojot VXLAN vai GRE protokola iekapsulēšanu, lai lietotājiem nodrošinātu ērti lietojamus tīkla pakalpojumus. Apakštīkls un pārklājuma tīkls ir saistīti un atdalīti, un tie ir saistīti viens ar otru un var attīstīties neatkarīgi.
Tīkla pamatā ir apakštīkls. Ja apakštīkls ir nestabils, uzņēmumam nav SLA. Pēc trīsslāņu tīkla arhitektūras un Fat-Tree tīkla arhitektūras datu centra tīkla arhitektūra pāriet uz Spine-Leaf arhitektūru, kas ievadīja CLOS tīkla modeļa trešo pielietojumu.
Tradicionālā datu centra tīkla arhitektūra
Trīs slāņu dizains
No 2004. līdz 2007. gadam trīs līmeņu tīkla arhitektūra bija ļoti populāra datu centros. Tai ir trīs slāņi: kodolslānis (tīkla ātrdarbīgās komutācijas mugurkauls), apkopošanas slānis (kas nodrošina uz politikām balstītu savienojamību) un piekļuves slānis (kas savieno darbstacijas ar tīklu). Modelis ir šāds:
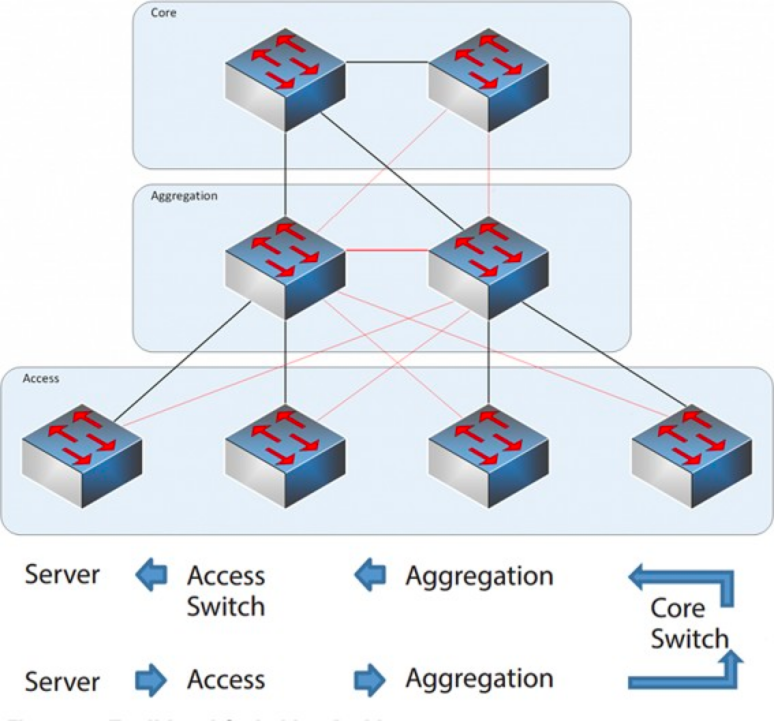
Trīsslāņu tīkla arhitektūra
Galvenais slānis: Galvenie slēdži nodrošina ātrdarbīgu pakešu pārsūtīšanu uz datu centru un no tā, savienojamību ar vairākiem apkopošanas slāņiem un elastīgu L3 maršrutēšanas tīklu, kas parasti apkalpo visu tīklu.
Apkopošanas slānis: Apkopošanas slēdzis izveido savienojumu ar piekļuves slēdzi un nodrošina citus pakalpojumus, piemēram, ugunsmūri, SSL atslodzes atsaisti, ielaušanās noteikšanu, tīkla analīzi utt.
Piekļuves slānis: Piekļuves slēdži parasti atrodas plaukta augšpusē, tāpēc tos sauc arī par ToR (Plaukta augšdaļas) slēdžiem, un tie fiziski izveido savienojumu ar serveriem.
Parasti agregācijas slēdzis ir robežpunkts starp L2 un L3 tīkliem: L2 tīkls atrodas zem agregācijas slēdža, bet L3 tīkls ir virs tā. Katra agregācijas slēdžu grupa pārvalda piegādes punktu (POD), un katrs POD ir neatkarīgs VLAN tīkls.
Tīkla cilpas un aptverošā koka protokols
Cilpu veidošanos galvenokārt izraisa neskaidrības neskaidru galamērķa ceļu dēļ. Veidojot tīklus, lietotāji uzticamības nodrošināšanai parasti izmanto liekas ierīces un liekus savienojumus, tāpēc neizbēgami veidojas cilpas. 2. slāņa tīkls atrodas vienā un tajā pašā apraides domēnā, un apraides paketes cilpā tiks pārraidītas atkārtoti, veidojot apraides vētru, kas var izraisīt portu bloķēšanu un iekārtu paralīzi. Tāpēc, lai novērstu apraides vētras, ir jānovērš cilpu veidošanās.
Lai novērstu cilpu veidošanos un nodrošinātu uzticamību, rezerves ierīces un rezerves saites var pārvērst tikai par rezerves ierīcēm un rezerves saitēm. Tas nozīmē, ka normālos apstākļos rezerves ierīču porti un saites tiek bloķētas un nepiedalās datu pakešu pārsūtīšanā. Tikai tad, kad pašreizējā pārsūtīšanas ierīce, ports vai saite nedarbojas pareizi, kā rezultātā rodas tīkla pārslodze, tiks atvērtas rezerves ierīču porti un saites, lai tīklu varētu atjaunot normālā stāvoklī. Šo automātisko vadību īsteno Spanning Tree protokols (STP).
Skatīšanas koka protokols darbojas starp piekļuves slāni un uztveršanas slāni, un tā pamatā ir skata koka algoritms, kas darbojas katrā STP iespējotā tiltā un ir īpaši izstrādāts, lai izvairītos no tilta cilpām lieku ceļu klātbūtnē. STP izvēlas labāko datu ceļu ziņojumu pārsūtīšanai un neļauj tās saites, kas nav daļa no skata koka, atstājot tikai vienu aktīvu ceļu starp jebkuriem diviem tīkla mezgliem, un otra augšupsaite tiks bloķēta.
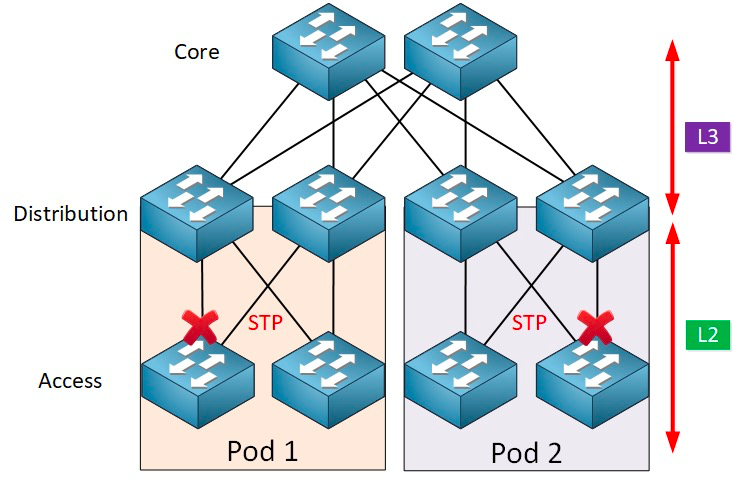
STP ir daudz priekšrocību: tas ir vienkāršs, viegli pievienojams un lietojams, un tam nepieciešama ļoti maza konfigurācija. Katra poda mašīnas pieder vienam un tam pašam VLAN, tāpēc serveris var patvaļīgi migrēt atrašanās vietu poda ietvaros, nemainot IP adresi un vārteju.
Tomēr STP nevar izmantot paralēlus pāradresācijas ceļus, kas vienmēr atspējos liekos ceļus VLAN ietvaros. STP trūkumi:
1. Lēna topoloģijas konverģence. Kad mainās tīkla topoloģija, aptverošā koka protokolam topoloģijas konverģences pabeigšanai nepieciešamas 50–52 sekundes.
2. nevar nodrošināt slodzes līdzsvarošanas funkciju. Ja tīklā ir cilpa, aptverošā koka protokols var tikai vienkārši bloķēt cilpu, lai saite nevarētu pārsūtīt datu paketes, tādējādi izšķērdējot tīkla resursus.
Virtualizācija un austrumu-rietumu satiksmes izaicinājumi
Pēc 2010. gada, lai uzlabotu skaitļošanas un krātuves resursu izmantošanu, datu centri sāka ieviest virtualizācijas tehnoloģiju, un tīklā sāka parādīties liels skaits virtuālo mašīnu. Virtuālā tehnoloģija pārveido serveri vairākos loģiskos serveros, katra virtuālā mašīna var darboties neatkarīgi, tai ir sava operētājsistēma, lietotne, sava neatkarīga MAC adrese un IP adrese, un tie izveido savienojumu ar ārējo entītiju, izmantojot servera iekšpusē esošo virtuālo slēdzi (vSwitch).
Virtualizācijai ir papildu prasība: virtuālo mašīnu tiešraides migrācija, iespēja pārvietot virtuālo mašīnu sistēmu no viena fiziskā servera uz citu, vienlaikus saglabājot normālu pakalpojumu darbību virtuālajās mašīnās. Šis process nav jutīgs pret gala lietotājiem, administratori var elastīgi piešķirt servera resursus vai remontēt un jaunināt fiziskos serverus, neietekmējot lietotāju normālu lietošanu.
Lai nodrošinātu pakalpojuma nepārtrauktību migrācijas laikā, ir nepieciešams ne tikai nemainīt virtuālās mašīnas IP adresi, bet arī saglabāt virtuālās mašīnas darbības stāvokli (piemēram, TCP sesijas stāvokli), tāpēc virtuālās mašīnas dinamisko migrāciju var veikt tikai tajā pašā 2. slāņa domēnā, bet ne visā 2. slāņa domēna migrācijas laikā. Tas rada nepieciešamību pēc lielākiem 2. slāņa domēniem no piekļuves slāņa uz galveno slāni.
Tradicionālajā lielajā 2. slāņa tīkla arhitektūrā L2 un L3 sadalījuma punkts atrodas kodola komutatorā, un datu centrs zem kodola komutatora ir pilnīgs apraides domēns, tas ir, L2 tīkls. Tādā veidā var realizēt ierīču izvietošanas un atrašanās vietas migrācijas patvaļīgumu, un nav nepieciešams modificēt IP un vārtejas konfigurāciju. Dažādi L2 tīkli (VLAN) tiek maršrutēti caur kodola komutatoriem. Tomēr kodola komutatoram saskaņā ar šo arhitektūru ir jāuztur milzīga MAC un ARP tabula, kas izvirza augstas prasības kodola komutatora iespējām. Turklāt piekļuves komutators (TOR) ierobežo arī visa tīkla mērogu. Tas galu galā ierobežo tīkla mērogu, tīkla paplašināšanu un elastības iespējas, un kavēšanās problēma visos trijos plānošanas līmeņos nevar apmierināt nākotnes biznesa vajadzības.
No otras puses, virtualizācijas tehnoloģijas radītā austrumu-rietumu datplūsma rada arī izaicinājumus tradicionālajam trīs slāņu tīklam. Datu centra datplūsmu var plaši iedalīt šādās kategorijās:
Ziemeļu-dienvidu satiksme:Datplūsma starp klientiem ārpus datu centra un datu centra serveri vai datplūsma no datu centra servera uz internetu.
Austrumu-rietumu satiksme:Datplūsma starp serveriem datu centrā, kā arī datplūsma starp dažādiem datu centriem, piemēram, atkopšana pēc avārijas starp datu centriem, saziņa starp privātiem un publiskiem mākoņiem.
Virtualizācijas tehnoloģiju ieviešana padara lietojumprogrammu izvietošanu arvien izkliedētāku, un "blakusparādība" ir tā, ka palielinās datplūsma austrumu-rietumu virzienā.
Tradicionālās trīs līmeņu arhitektūras parasti ir paredzētas satiksmei ziemeļu-dienvidu virzienā.Lai gan to var izmantot satiksmei virzienā no austrumiem uz rietumiem, tas galu galā var nedarboties kā paredzēts.
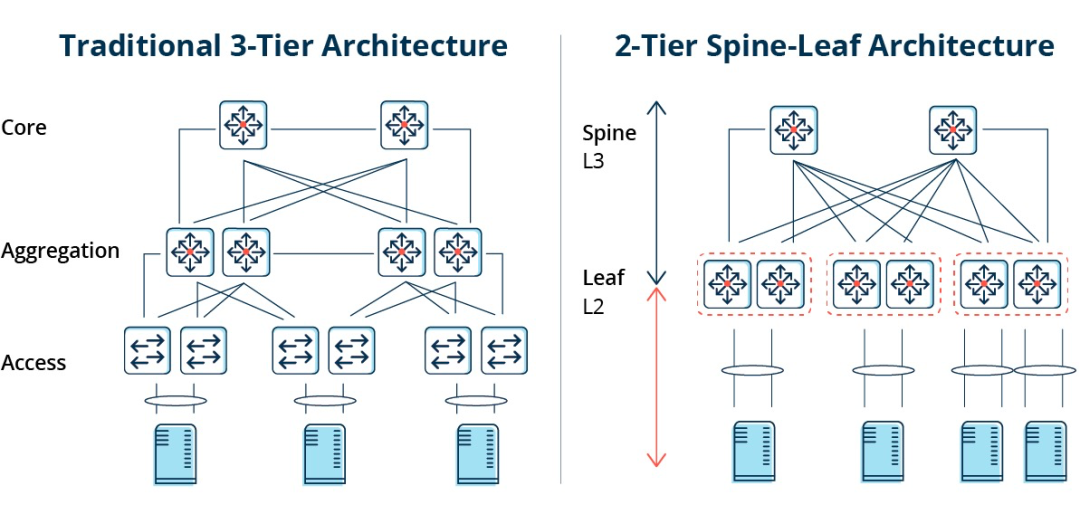
Tradicionālā trīs līmeņu arhitektūra salīdzinājumā ar mugurkaula-lapu arhitektūru
Trīs līmeņu arhitektūrā austrumu-rietumu virziena datplūsma jāpārsūta caur ierīcēm apkopošanas un pamata slāņos. Tā nevajadzīgi plūst caur daudziem mezgliem. (Serveris -> Piekļuve -> Apkopošana -> Pamata komutators -> Apkopošana -> Piekļuves komutators -> Serveris)
Tādēļ, ja liels austrumu-rietumu virziena datplūsmas apjoms tiek tērēts caur tradicionālo trīs līmeņu tīkla arhitektūru, ierīces, kas pievienotas vienam un tam pašam komutatora portam, var konkurēt par joslas platumu, kā rezultātā gala lietotājiem ir slikts reakcijas laiks.
Tradicionālās trīsslāņu tīkla arhitektūras trūkumi
Var redzēt, ka tradicionālajai trīsslāņu tīkla arhitektūrai ir daudz trūkumu:
Joslas platuma zudumi:Lai novērstu cilpu veidošanos, STP protokols parasti tiek palaists starp apkopošanas slāni un piekļuves slāni, lai tikai viena piekļuves komutatora augšupsaite faktiski pārraidītu datplūsmu, bet pārējās augšupsaites tiktu bloķētas, kā rezultātā tiktu izšķērdēta joslas platums.
Grūtības liela mēroga tīkla izvietošanā:Paplašinoties tīkla mērogam, datu centri tiek izkliedēti dažādās ģeogrāfiskās vietās, virtuālās mašīnas ir jāizveido un jāmigrē jebkur, un to tīkla atribūti, piemēram, IP adreses un vārtejas, paliek nemainīgi, kas prasa FAT Layer 2 atbalstu. Tradicionālajā struktūrā migrāciju nevar veikt.
Austrumu-rietumu satiksmes trūkums:Trīs līmeņu tīkla arhitektūra galvenokārt ir paredzēta ziemeļu-dienvidu satiksmei, lai gan tā atbalsta arī austrumu-rietumu satiksmi, taču trūkumi ir acīmredzami. Kad austrumu-rietumu satiksme ir liela, spiediens uz agregācijas slāni un pamata slāņa komutatoriem ievērojami palielināsies, un tīkla lielums un veiktspēja būs ierobežota ar agregācijas slāni un pamata slāni.
Tas liek uzņēmumiem nonākt izmaksu un mērogojamības dilemmā:Liela mēroga augstas veiktspējas tīklu atbalstam ir nepieciešams liels skaits konverģences slāņa un galvenā slāņa iekārtu, kas ne tikai rada augstas izmaksas uzņēmumiem, bet arī prasa, lai tīkls tiktu plānots iepriekš, veidojot tīklu. Ja tīkla mērogs ir mazs, tas novedīs pie resursu izšķiešanas, un, tīkla mērogam turpinot paplašināties, to ir grūti paplašināt.
Mugurkaula-lapas tīkla arhitektūra
Kas ir Spine-Leaf tīkla arhitektūra?
Reaģējot uz iepriekš minētajām problēmām,Ir parādījies jauns datu centra dizains — mugurkaula-lapu tīkla arhitektūra, ko mēs saucam par lapu grēdu tīklu.
Kā norāda nosaukums, arhitektūrai ir mugurkaula slānis un lapu slānis, tostarp mugurkaula slēdži un lapu slēdži.
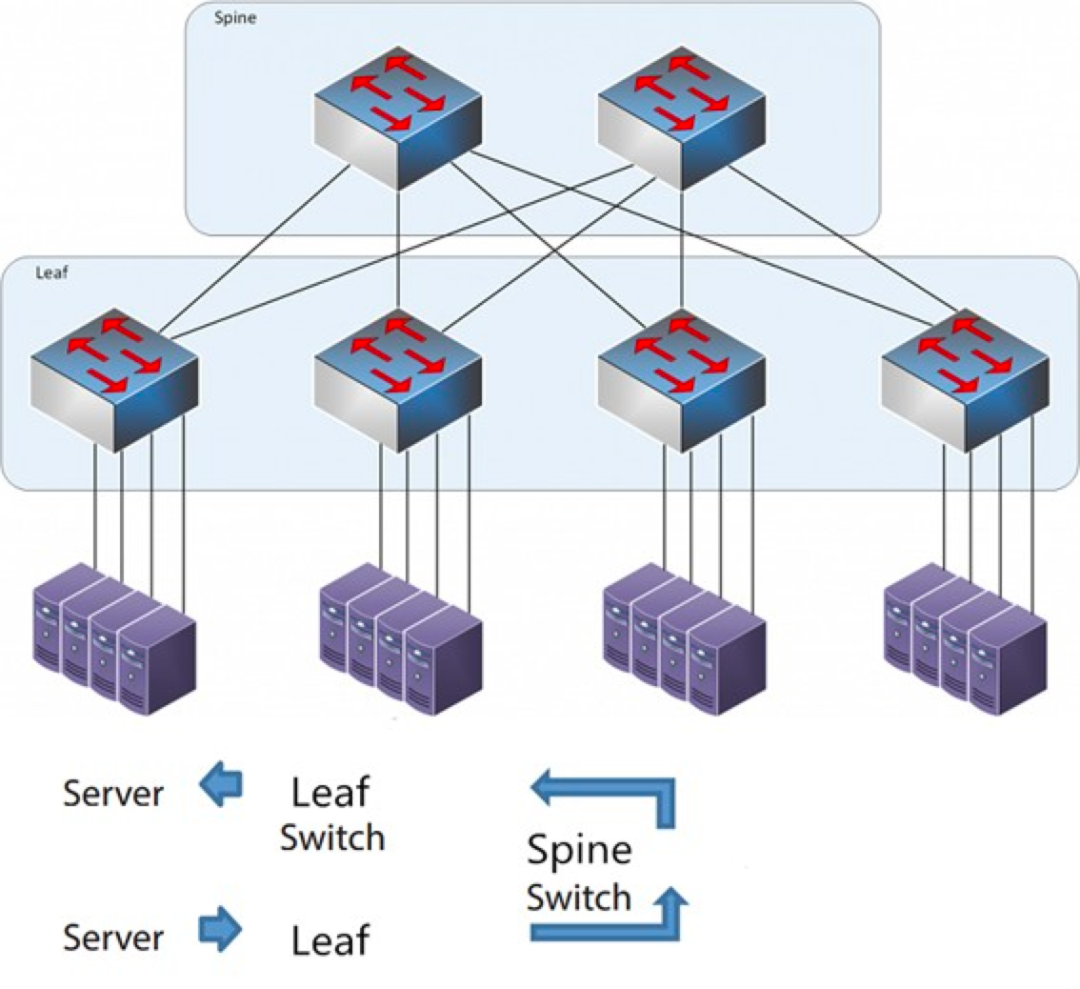
Mugurkaula-lapas arhitektūra
Katrs lapu slēdzis ir savienots ar visiem kores slēdžiem, kas nav tieši savienoti viens ar otru, veidojot pilna tīkla topoloģiju.
Mugurkaula un lapas savienojuma gadījumā savienojums no viena servera uz otru notiek caur vienādu ierīču skaitu (Serveris -> Lapa -> Mugurkaula slēdzis -> Lapu slēdzis -> Serveris), kas nodrošina paredzamu latentumu. Jo paketei, lai sasniegtu galamērķi, ir jāiziet tikai caur vienu mugurkaulu un vēl vienu lapu.
Kā darbojas Spine-Leaf?
Leaf Switch: Tas ir līdzvērtīgs piekļuves slēdzim tradicionālajā trīs līmeņu arhitektūrā un tieši savienojas ar fizisko serveri kā TOR (Top Of Rack — plaukta augšdaļa). Atšķirība no piekļuves slēdža ir tāda, ka L2/L3 tīkla demarkācijas punkts tagad atrodas uz Leaf slēdža. Leaf slēdzis atrodas virs trīsslāņu tīkla, un Leaf slēdzis atrodas zem neatkarīgā L2 apraides domēna, kas atrisina lielo divslāņu tīkla BUM problēmu. Ja diviem Leaf serveriem ir jāsazinās, tiem jāizmanto L3 maršrutēšana un jāpārsūta informācija caur Spine slēdzi.
Mugurkaula slēdzis: Līdzvērtīgs kodola slēdzim. ECMP (vienlīdzīgu izmaksu vairāku ceļu) protokols tiek izmantots, lai dinamiski atlasītu vairākus ceļus starp Spine un Leaf slēdžiem. Atšķirība ir tāda, ka Spine tagad vienkārši nodrošina elastīgu L3 maršrutēšanas tīklu Leaf slēdzim, tāpēc datu centra ziemeļu-dienvidu trafiku var novirzīt no Spine slēdža, nevis tieši. Ziemeļu-dienvidu trafiku var novirzīt no malas slēdža paralēli Leaf slēdzim uz WAN maršrutētāju.
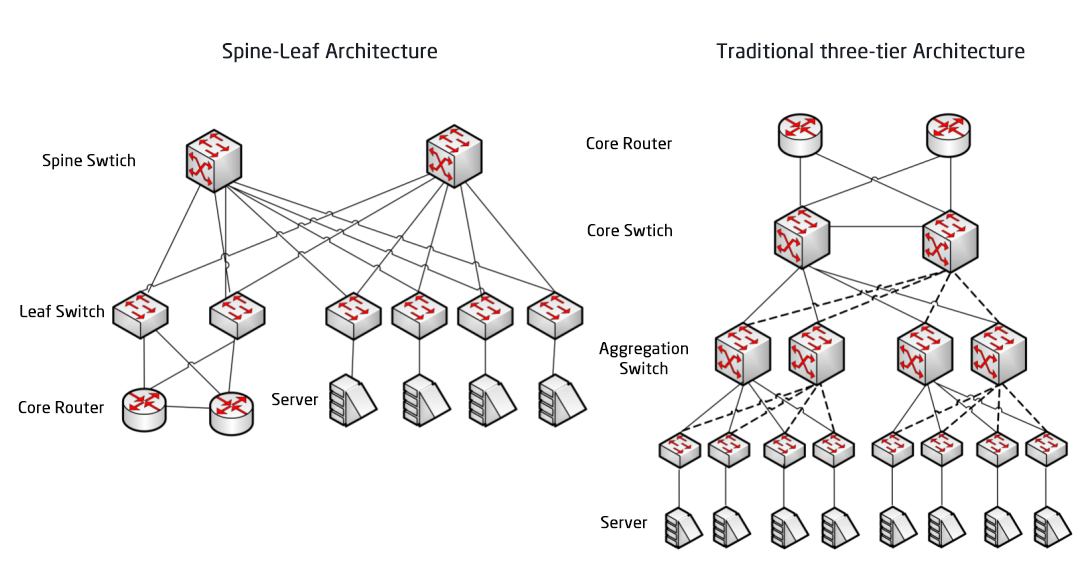
Salīdzinājums starp Spine/Leaf tīkla arhitektūru un tradicionālo trīsslāņu tīkla arhitektūru
Mugurkaula-lapas priekšrocības
Dzīvoklis:Plakans dizains saīsina komunikācijas ceļu starp serveriem, kā rezultātā samazinās latentums, kas var ievērojami uzlabot lietojumprogrammu un pakalpojumu veiktspēju.
Laba mērogojamība:Ja joslas platums ir nepietiekams, palielinot kores slēdžu skaitu, joslas platumu var horizontāli palielināt. Palielinoties serveru skaitam, varam pievienot lapu slēdžus, ja portu blīvums nav pietiekams.
Izmaksu samazināšana: satiksme ziemeļu un dienvidu virzienā, kas iziet vai nu no lapu mezgliem, vai no grēdu mezgliem. Austrumu-rietumu plūsma, sadalīta pa vairākiem ceļiem. Tādā veidā lapu grēdu tīklā var izmantot fiksētas konfigurācijas slēdžus bez nepieciešamības pēc dārgiem modulāriem slēdžiem, un tādējādi samazināt izmaksas.
Zema latentuma un pārslodzes novēršana:Datu plūsmām Leaf Ridge tīklā ir vienāds lēcienu skaits tīklā neatkarīgi no avota un galamērķa, un jebkuri divi serveri ir sasniedzami viens no otra trīs lēcienu režīmā Leaf -> Spine -> Leaf. Tas izveido tiešāku datplūsmas ceļu, kas uzlabo veiktspēju un samazina sastrēgumus.
Augsta drošība un pieejamība:STP protokols tiek izmantots tradicionālajā trīs līmeņu tīkla arhitektūrā, un ierīces atteices gadījumā tā atkārtoti konverģē, ietekmējot tīkla veiktspēju vai pat izraisot kļūmi. Lapu grēdas arhitektūrā ierīces atteices gadījumā nav nepieciešams atkārtoti konverģēt, un datplūsma turpina plūst pa citiem parastajiem ceļiem. Tīkla savienojamība netiek ietekmēta, un joslas platums tiek samazināts tikai par vienu ceļu, ar nelielu ietekmi uz veiktspēju.
Slodzes līdzsvarošana, izmantojot ECMP, ir labi piemērota vidēm, kurās tiek izmantotas centralizētas tīkla pārvaldības platformas, piemēram, SDN. SDN ļauj vienkāršot datplūsmas konfigurēšanu, pārvaldību un pāradresēšanu bloķēšanas vai saites kļūmes gadījumā, padarot viedās slodzes līdzsvarošanas pilna režģa topoloģiju par relatīvi vienkāršu konfigurēšanas un pārvaldības veidu.
Tomēr Spine-Leaf arhitektūrai ir daži ierobežojumi:
Viens no trūkumiem ir tas, ka slēdžu skaits palielina tīkla izmēru. Lapu grēdu tīkla arhitektūras datu centram ir jāpalielina slēdžu un tīkla iekārtu skaits proporcionāli klientu skaitam. Palielinoties resursdatoru skaitam, ir nepieciešams liels skaits lapu slēdžu, lai izveidotu savienojumu ar grēdu slēdzi.
Tiešai grēdu un lapu slēdžu savienošanai ir nepieciešama saskaņošana, un kopumā saprātīga joslas platuma attiecība starp lapu un grēdu slēdžiem nedrīkst pārsniegt 3:1.
Piemēram, lapu komutatorā ir 48 klienti ar 10 Gb/s ātrumu un kopējo portu jaudu 480 Gb/s. Ja katra lapu komutatora četras 40 G augšupsaites pieslēgvietas ir savienotas ar 40 G kores komutatoru, tā augšupsaites jauda būs 160 Gb/s. Attiecība ir 480:160 jeb 3:1. Datu centru augšupsaites parasti ir 40 G vai 100 G, un laika gaitā tās var migrēt no sākuma punkta 40 G (Nx 40 G) uz 100 G (Nx 100 G). Ir svarīgi atzīmēt, ka augšupsaitei vienmēr jādarbojas ātrāk nekā lejupsaitei, lai nebloķētu portu saiti.
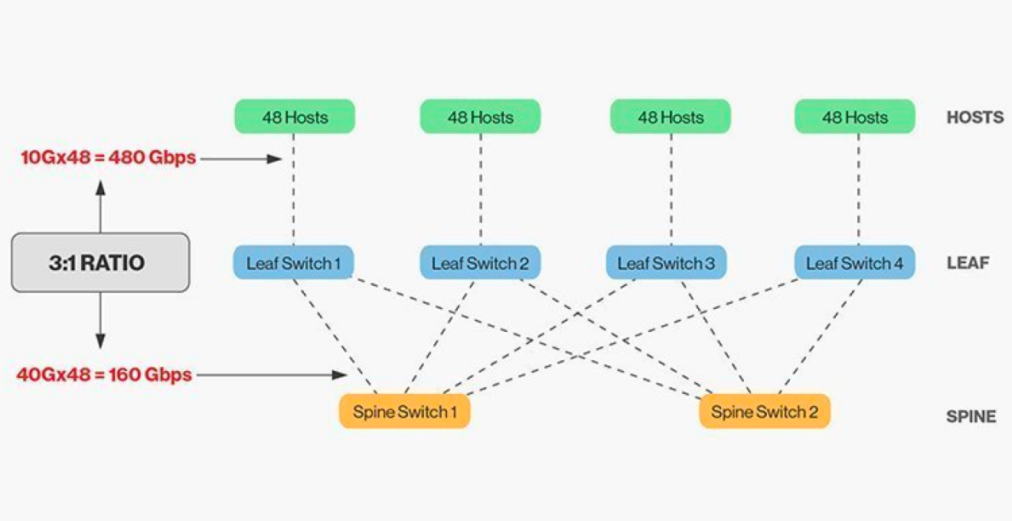
Spine-Leaf tīkliem ir arī skaidras elektroinstalācijas prasības. Tā kā katram lapu mezglam jābūt savienotam ar katru mugurkaula komutatoru, mums ir jāuzstāda vairāk vara vai optisko šķiedru kabeļu. Starpsavienojumu attālums palielina izmaksas. Atkarībā no attāluma starp savstarpēji savienotajiem slēdžiem Spine-Leaf arhitektūrai nepieciešamo augstas klases optisko moduļu skaits ir desmitiem reižu lielāks nekā tradicionālajai trīs līmeņu arhitektūrai, kas palielina kopējās izvietošanas izmaksas. Tomēr tas ir novedis pie optisko moduļu tirgus izaugsmes, īpaši attiecībā uz ātrdarbīgiem optiskajiem moduļiem, piemēram, 100G un 400G.
Publicēšanas laiks: 2026. gada 26. janvāris



